GPT-Driven General Web Crawler
Language models led by GPT have completely changed the way crawlers are written. Previously, special configuration or handling was required for the crawler of each website (as each website has its unique structure) to extract the desired information. But with GPT, it is not impossible for a crawler to extract the desired information from all websites. For this purpose, I wrote a general crawler that uses GPT to extract information during the crawling process and open-sourced it on Github.
1 Introduction
GPT-Web-Crawler is a web crawler based on Python and Puppeteer that can crawl web pages and extract content from them (including the webpage’s title, URL, keywords, description, all text content, all images, and screenshots). It is very easy to use, requiring only a few lines of code to crawl web pages and extract content from them, making it very suitable for people who are not familiar with web crawling but want to extract content from web pages.
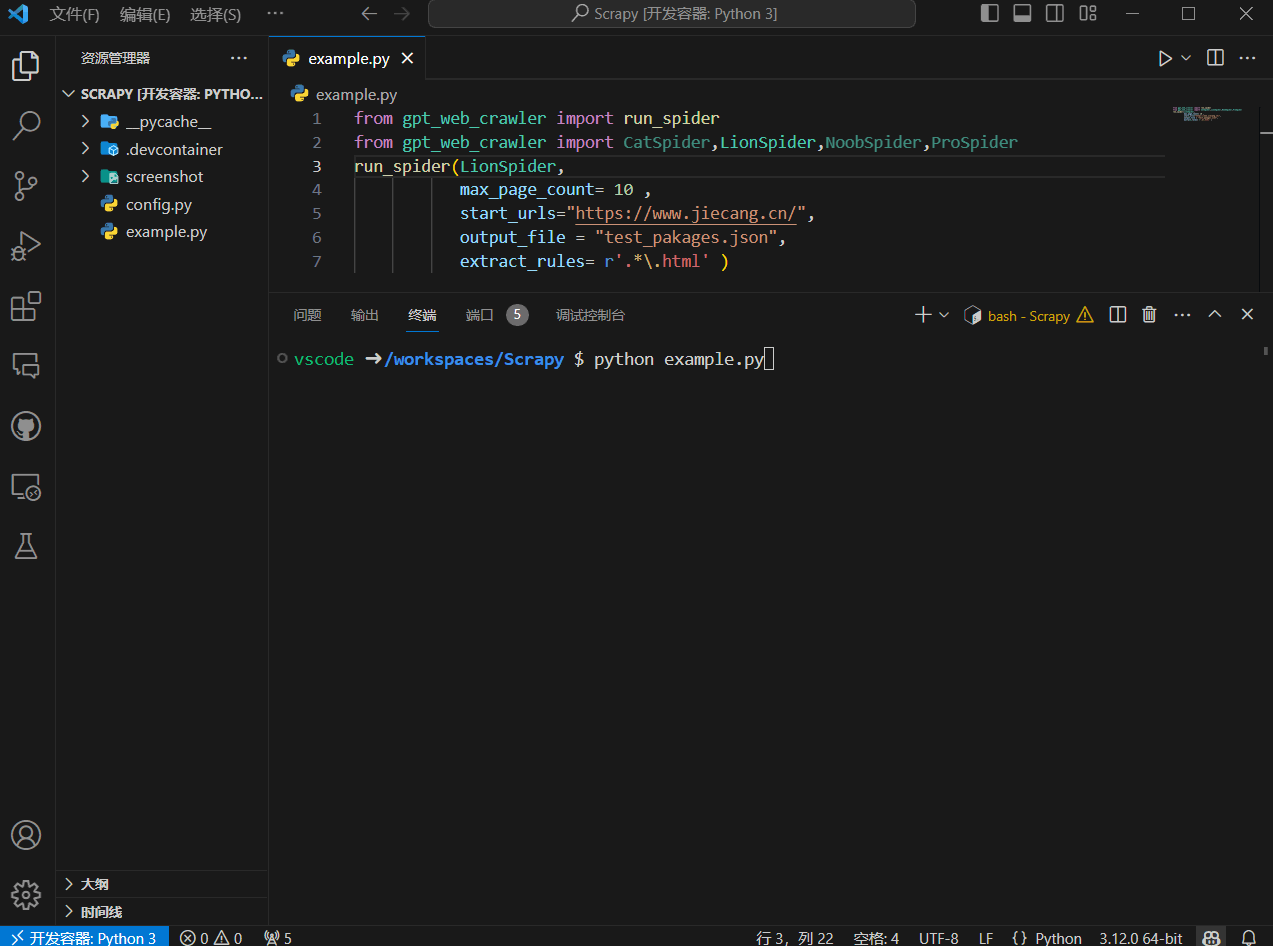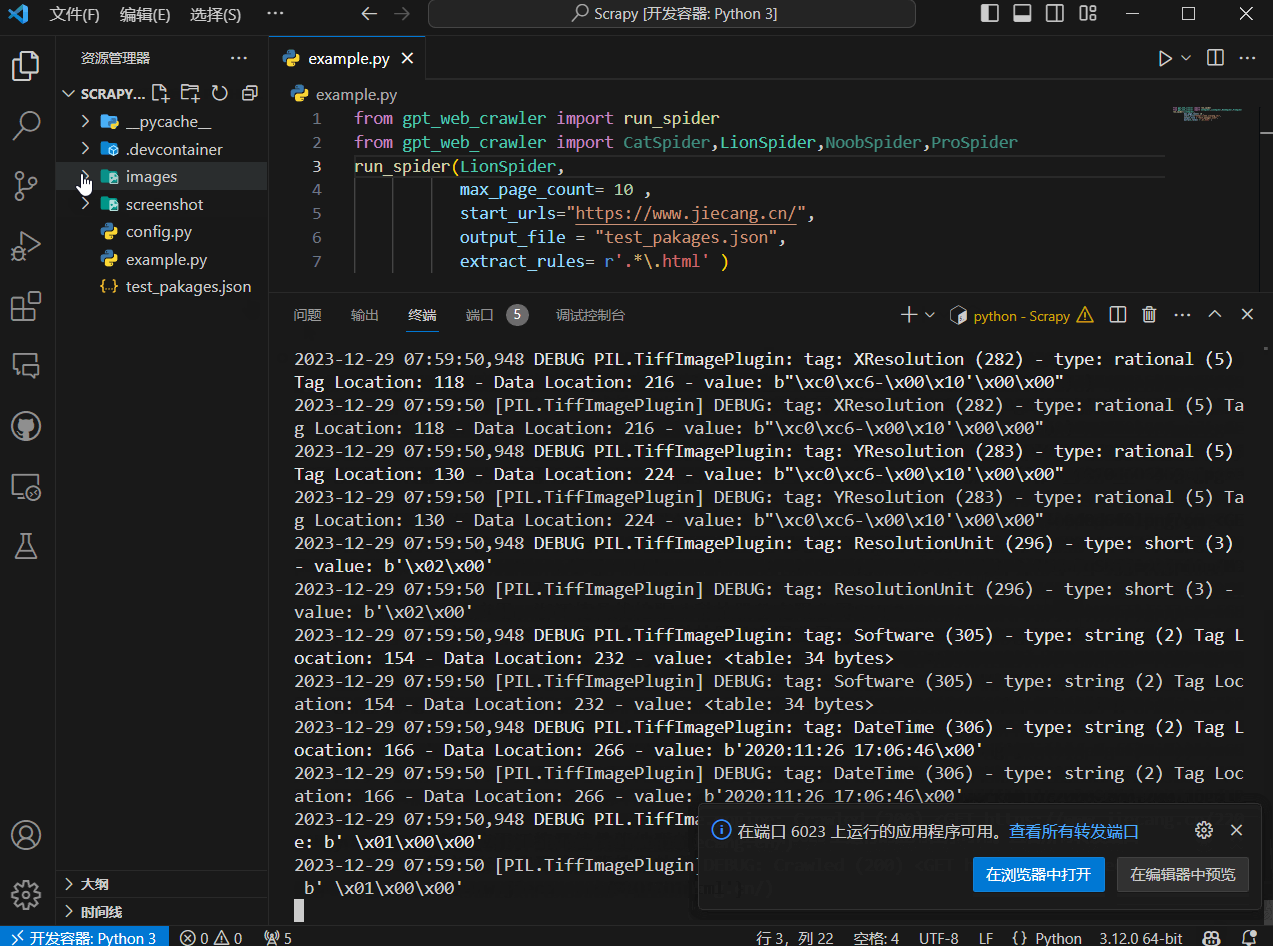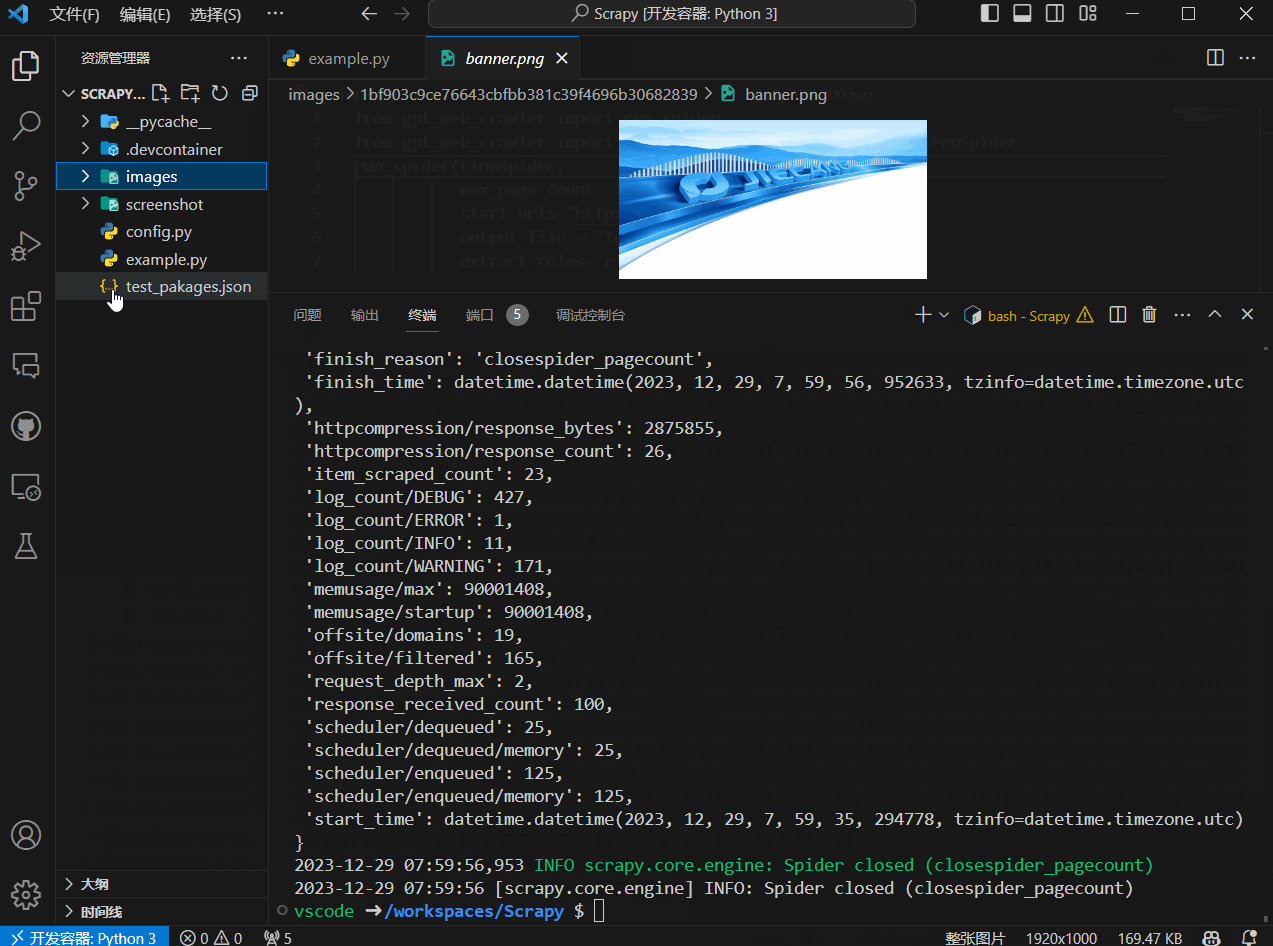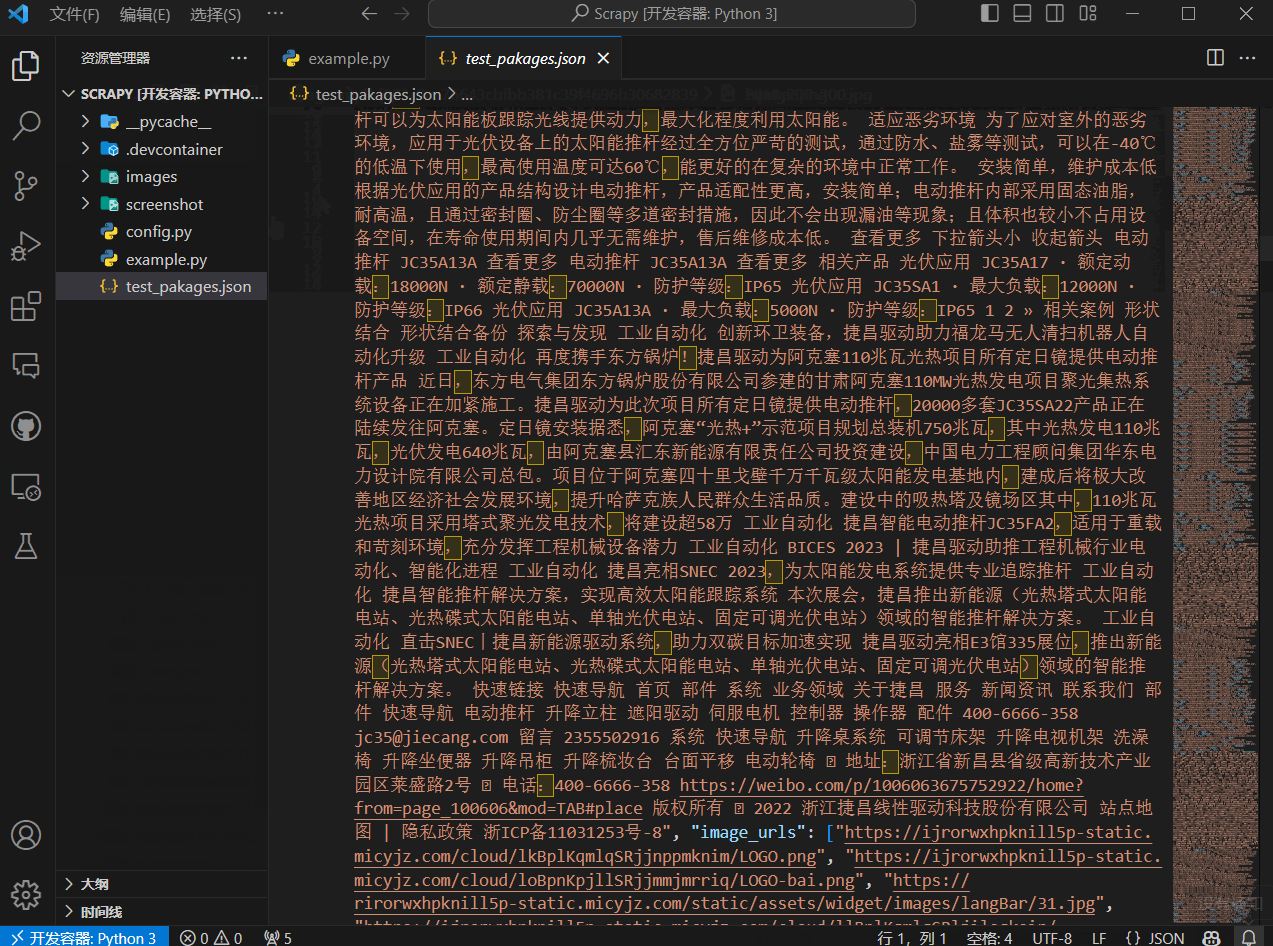
The output of the crawler can be a JSON file, which can be easily converted to a CSV file, imported into a database, or used to build an AI agent.
2 Getting Started
Step 1. Install the package.
|
|
Step 2. Copy config_template.py and rename it to config.py. Then, edit the config.py file to configure the OpenAI API key and other settings if you need ProSpider to help you extract content from web pages. If you do not need AI to help you extract content from web pages, you can leave the config.py file unchanged.
Step 3. Run the following code to start a crawler.
|
|
3 Crawlers
In the code above, NoobSpider was used. There are four types of crawlers in this package, and they can extract different content from web pages. The table below shows their differences.
| Crawler Type | Description | Returned Content |
|---|---|---|
| NoobSpider | Extracts basic webpage information | - title - URL - keywords - description - body: all text content of the webpage |
| CatSpider | Extracts webpage information with screenshots | - title - URL - keywords - description - body: all text content of the webpage - screenshot_path: screenshot path |
| ProSpider | Extracts basic information and uses AI to extract content | - title - URL - keywords - description - body: all text content of the webpage - ai_extract_content: GPT extracted main text |
| LionSpider | Extracts basic information and all images | - title - URL - keywords - description - body: all text content of the webpage - directory: directory of all images on the webpage |
3.1 Cat Spider
Cat spider is a crawler that can take screenshots of web pages. It is based on Noob spider and uses Puppeteer to simulate browser operations to take screenshots of the entire webpage and save them as images. So when you use Cat spider, you need to install Puppeteer first.
|
|
 Alipay
Alipay
 PayPal
PayPal
 WeChat Pay
WeChat Pay